
Google翻訳でジェンダーバイアスを減らすためのスケーラブルなアプローチ 第01回 20年05月 / 最終更新:2020.05.14
目次
こんにちは。野田貴子です。今回から海外のWeb関連のAIニュースを意訳して紹介していきます。興味がある方はご覧ください。
機械学習(ML)を使用している翻訳システムでは、トレーニングデータに反映される社会的なバイアスのせいで翻訳結果が歪められることがあります。その1つはジェンダーバイアスです。これは性別を明記する言語としない言語の間で翻訳をする際に、より顕著に現れます。たとえば、Google翻訳はこれまで「この方は医者です」のトルコ語を男性形に翻訳し、「この方は看護師です」のトルコ語を女性形に翻訳していました。
GoogleのAI原則では不当なバイアスを作成したり強化しないことを重要視しているため、これに沿って、2018年12月に性別を考慮した翻訳を発表しました。この機能により、元の言語では性別を問わない文章を翻訳する際に、女性と男性の両方の翻訳の選択肢を表示するようになりました。この作業では、性別に依存しない文章の検出、性別を考慮した翻訳の生成、そして正確性のチェックを含む3段階のアプローチを開発しました。この結果、トルコ語から英語へ性別を考慮した翻訳ができるようになり、Google翻訳で一番よく使われる英語からスペイン語への翻訳でもこのアプローチをスケールしました。
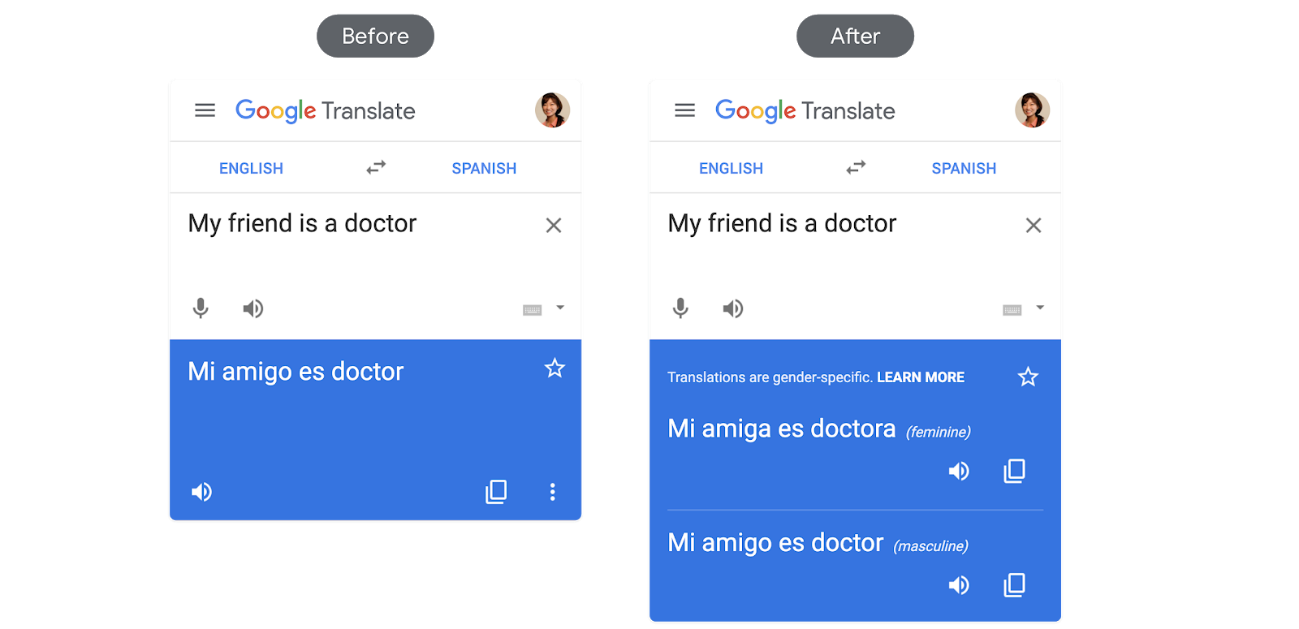
左:性別を明記していない英語のフレーズを、性別を明記するスペイン語に翻訳した初期の例。これは偏った結果のみが表示されています。
右:新しい翻訳では、女性と男性の両方の選択肢が表示されています。
しかし、このアプローチをより多くの言語に適用してみると、スケーリングに問題があることが明らかになりました。具体的には、ニュートラル機械翻訳(NMT)システムを使用して男性と女性の翻訳を別々に生成すると、最大40%の文章が適切な翻訳を表示することができませんでした。なぜなら、この2つの翻訳は、性別以外の表現が完全に同じにはならなかったからです。さらに、原文のジェンダーニュートラル性を検出するための機能を構築すためにデータが集中してしまいました。
そこで今日リリースするものは、英語からスペイン語への性別を考慮した翻訳と、最初の翻訳を書き直したり後から編集したりすることでジェンダーバイアスに対処するという改良版アプローチです。このアプローチではジェンダーニュートラルの検出を必要としないため、特にジェンダーニュートラルな言語から英語に翻訳する場合によりスケーラブルになりました。このアプローチを使用して、性別を考慮した翻訳をスケールし、フィンランド語、ハンガリー語、ペルシャ語から英語に翻訳しました。また、新たな書き直しベースの方法を使用して、従来のトルコ語から英語への翻訳システムを置き換えました。
書き直しにもとづく、性別を考慮した翻訳
書き直しベースの方法で最初にやることは、初期翻訳を生成することです。次に、翻訳をレビューして、性別を明記していない原文が性別を明記する訳文になってしまった原因を特定します。そして文単位のリライターを適用して、別の性別の翻訳を生成します。最後に、最初の翻訳と書き直された翻訳の両方がレビューされ、唯一の違いが性別のみであることを確認します。

上:従来のアプローチ
下:新しい書き直しベースのアプローチ
リライター
リライターの作成には、男性と女性の両方の翻訳を含むフレーズのペアで構成される数百万のトレーニングサンプルの生成が含まれていました。そのようなデータはすぐに利用できなかったため、この目的のために新しいデータセットを生成しました。大規模な単一言語のデータセットから始めて、性別代名詞を男性から女性、またはその逆に交換することにより、プログラム的に候補の書き直しを生成しました。文脈に応じて複数の有効な候補が存在する可能性があるため、正しいものを選択するためのメカニズムが必要でした(たとえば、女性の代名詞「her」は「him」または「his」のいずれかに交換でき、男性的な代名詞「his」は「her」または「hers」に交換できます)。この結びつきを解決するためには構文解析または言語モデルを使用します。構文解析モデルは、各言語のラベル付きデータセットを使用したトレーニングを必要とするため、教師なしで学習できる言語モデルよりもスケーラビリティが低くなります。そのため、数百万の英文でトレーニングされた内製言語モデルを使用して、最適な候補を選択しました。
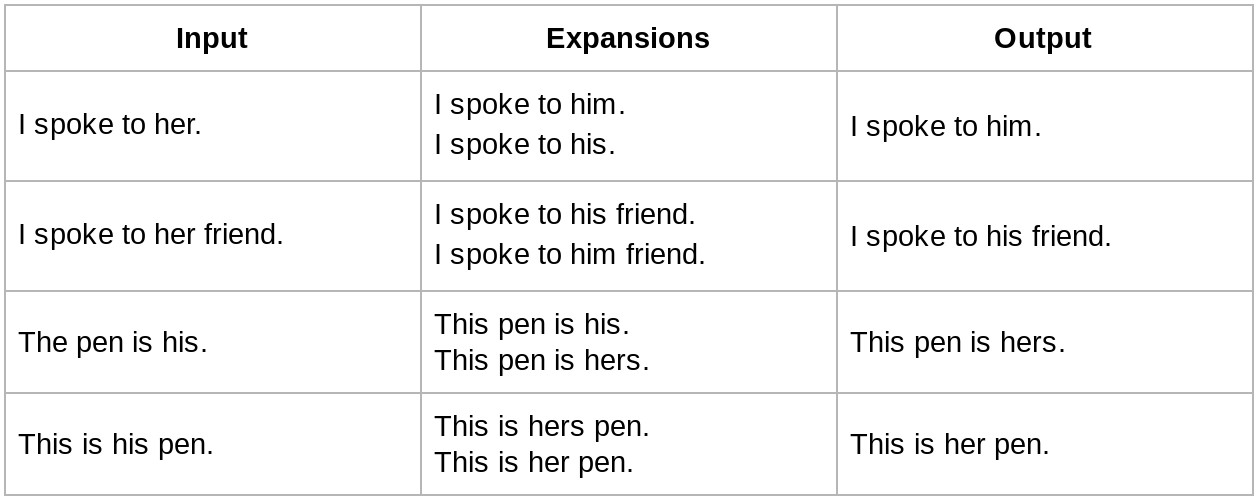
この表は、データ生成プロセスを示しています。入力から始め、候補を生成し、最後に言語モデルを使用して均衡を取ります。
上記のデータ生成プロセスにより、男性的な入力から女性的な出力へ、またはその逆のトレーニングデータが生成されます。これらの両方向からのデータを統合し、1層のトランスフォーマーベースのシーケンスからシーケンスへのモデルをトレーニングします。モデルの堅牢性を高めるために、トレーニングデータに句読点や大文字小文字のバリエーションを導入します。最終的なモデルでは、リクエストされた男性または女性の書き直しを確実に99%生成できるようになりました。
評価
また、バイアス削減と呼ばれる新しい評価方法を考案しました。これは新しい翻訳システムでは既存のシステムからどれだけバイアスが削減されたのかを測定するものです。ここで「バイアス」とは、原文で指定されていない性別を翻訳の際に選んでしまうことと定義されています。たとえば、現在のシステムが90%の確率でバイアスされ、新しいシステムが45%の確率でバイアスされる場合、相対的にバイアスが50%減少したことになります。この測定基準を使用すると、新しいアプローチでは、ハンガリー語、フィンランド語、ペルシャ語から英語への翻訳のバイアスが90%以上減少しました。さらに既存のトルコ語から英語へのシステムのバイアスが60~95%改善されました。Googleのシステムは、平均97%の精度で性別を考慮した翻訳を行っています(つまり、性別を考慮した翻訳を表示することを決定した場合、97%の確率で適切な結果となっています)。
性別を考慮した翻訳の品質を向上させ、さらに4つの言語ペアにスケールすることで、最初のリリースから大きな進歩を遂げてきました。私たちは、Google翻訳におけるジェンダーバイアスへの取り組みをさらに進め、この作業をドキュメントレベルの翻訳にもスケールしていくことを計画しています。
※本コラムは以下の文章を意訳したものです。
引用元 https://ai.googleblog.com/2020/04/a-scalable-approach-to-reducing-gender.html
※本コラムは原文執筆者が公式に発表しているものでなく、翻訳者が独自に意訳しているものです。

