
YouTubeクリエーターのためのSmartReply 第04回 20年08月 / 最終更新:2022.06.09
目次
こんにちは。野田貴子です。今回から海外のWeb関連のAIニュースを意訳して紹介していきます。興味がある方はご覧ください。
--
SmartReply(https://research.google/pubs/pub45189/)がローンチされてから4年が経ちましたが、これまでに、Gmailローンチ(https://ai.googleblog.com/2017/05/efficient-smart-reply-now-for-gmail.html)やAndroid Messages(https://www.blog.google/products/messages/five-new-features-try-messages/)にてより多くのユーザーに、そして[Android Wear](https://ai.googleblog.com/2017/11/on-device-conversational-modeling-with.html)にてより多くのデバイスに拡大されました。開発者のみなさんは現在、Play Developer Console(https://android-developers.googleblog.com/2019/05/whats-new-in-play.html)内のレビューにSmartReplyを使用したり、MLKit(https://developers.google.com/ml-kit/language/smart-reply)やTFLite(https://www.tensorflow.org/lite/models/smart_reply/overview)で提供されているAPIを使ってオリジナル版をセットアップすることができます。各ローンチでは、タスク要件に合わせてSmartReplyのモデリングとサービングをカスタマイズするという特有の課題をクリアしてきました。
そしてこのたび、YouTube用に構築され、YouTube Studioに実装された最新のSmartReplyをご紹介できることをうれしく思います。このモデルは、計算効率が良く拡張された自己注意ネットワーク(dilated self-attention network)を用いてコメントと返信を学習し、初のクロスリンガル(多言語横断)で文字バイトベースのSmartReplyモデルを描いています。SmartReply for YouTubeは今は英語とスペイン語のクリエイター向けに提供されていますが、このアプローチのおかげで、将来的にSmartReplyをより多くの言語に拡げる作業が簡素化されることになります。
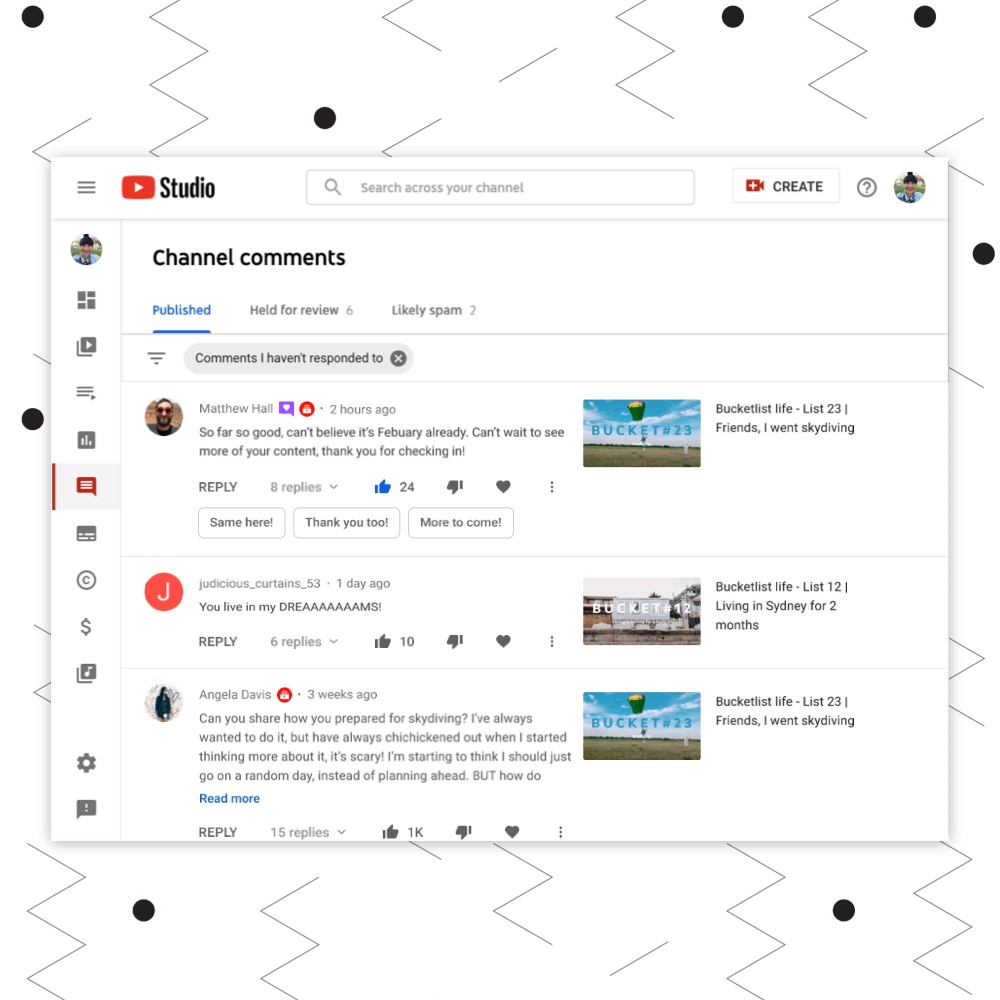
YouTubeのクリエイターは自分の動画に対して大量のコメントを受け取っています。さらに、YouTubeのクリエイターや視聴者のコミュニティの多様性が、コメントやディスカッション、動画の創造性にも反映されています。フォーマルな言葉で長くなりがちなメールに比べて、YouTubeのコメントには、言葉遣いの切り替え、略語、スラング、バラバラな句読点、絵文字の多用といった複雑なパターンが見られます。以下のコメント例にこの課題が現れています。

深層検索
SmartReply for Inbox(https://ai.googleblog.com/2015/11/computer-respond-to-this-email.html)の初期リリースでは、入力された電子メールを再帰ニューラルネットワーク(https://en.wikipedia.org/wiki/Recurrent_neural_network)で単語ごとにエンコードし、さらに別の単語レベルの再帰ニューラルネットワークで想定される返信をデコードしていました。このアプローチは表現力があるにもかかわらず、計算コストがかかってしまいます。代替案として、事前に定義しておいた提案リストから最も適切な応答を検索するシステムを設計すれば、同じ目的を達成できることがわかりました。
この検索システムは、メッセージとそれに対する提案を別々にエンコードしています。まず、テキストを前処理して単語と短いフレーズを抽出します。この前処理には言語の識別、トークン化、正規化が含まれていますが、これらに限定はしていません。次に、2つのニューラルネットワークがメッセージと提案を同時にそれぞれエンコードします。このように分解することで、提案のエンコーディングを事前に計算し、効率的な最大内積探索(Maximum Inner Product Search)(https://arxiv.org/abs/1903.10391)のデータ構造を使用して提案セットを検索することができます。この深層検索アプローチのおかげでSmartReplyをGmailに拡張することができ、それ以来、このアプローチは現在のYouTubeシステムを含むいくつかのSmartReplyシステムの基礎となっています。
単語を超えて
上述した以前のSmartReplyシステムは、限られた言語と狭いジャンルの文章に対してよく調整された、単語レベルの前処理に依存していました。このようなシステムは、YouTubeの場合には大きな課題に直面します。なぜならYouTubeの典型的なコメントには、絵文字やアスキーアート、言語の切り替えなど、種類が異なるコンテンツが含まれている可能性があるからです。私たちはこれを考慮した上で、バイトと文字言語のモデリングに関する最近の活動からインスピレーションを得て、前処理なしでテキストをエンコードすることにしました。このアプローチは、文字やバイトのシーケンスとなるテキストを与えるだけで、ディープなTransformer(https://arxiv.org/abs/1706.03762)ネットワークが、単語ベースのモデルと同等の品質で、単語やフレーズを新規にモデル化できることを実証する研究(https://arxiv.org/abs/1908.10322)によって裏付けられています。
初期の結果は、特に絵文字やタイプミスを含むコメントの処理において期待できるものでしたが、文字列が単語に相当するものよりも長かったり、Self-Attentionレイヤー(https://arxiv.org/abs/1706.03762)の計算の複雑さがシーケンスの長さと比例して二次関数的に増えるという事実があったために、この推測処理の速度は本番運用にとって遅すぎるものでした。私たちは、WaveNet(https://deepmind.com/blog/article/wavenet-generative-model-raw-audio)で適用されている拡張(dilation)技術と同じように、ネットワークの各レイヤーで時間削減(temporal reduction)レイヤーを適用してシーケンスの長さを短くすることで、計算量と品質の間でちょうどいいトレードオフが得られることを発見しました。
下図は、Contrastive Objective(https://arxiv.org/abs/1705.00652)を用いてネットワークを訓練することで、コメントと返信の両方をエンコードし、潜在的な表現の間の相互情報を最大化する、デュアルエンコーダーネットワークを示しています。このエンコーディングは、バイトのシーケンスが埋め込まれた後、トランスフォーマーにこれらを供給することから始まります。後続の各レイヤーへの入力は、等しいオフセットで文字の割合を落とすことによって削減されます。いくつかのトランスフォーマレイヤーを適用した後はシーケンスの長さは大幅に切り詰められ、計算の複雑さが大幅に減少します。このシーケンス圧縮スキームは、Average Pooling(https://www.tensorflow.org/api_docs/python/tf/keras/layers/AveragePooling2D)のような他の演算子で代用することもできますが、より良い使い心地を得られなかったため、シンプルな拡張(dilation)を使用することを選択しました。
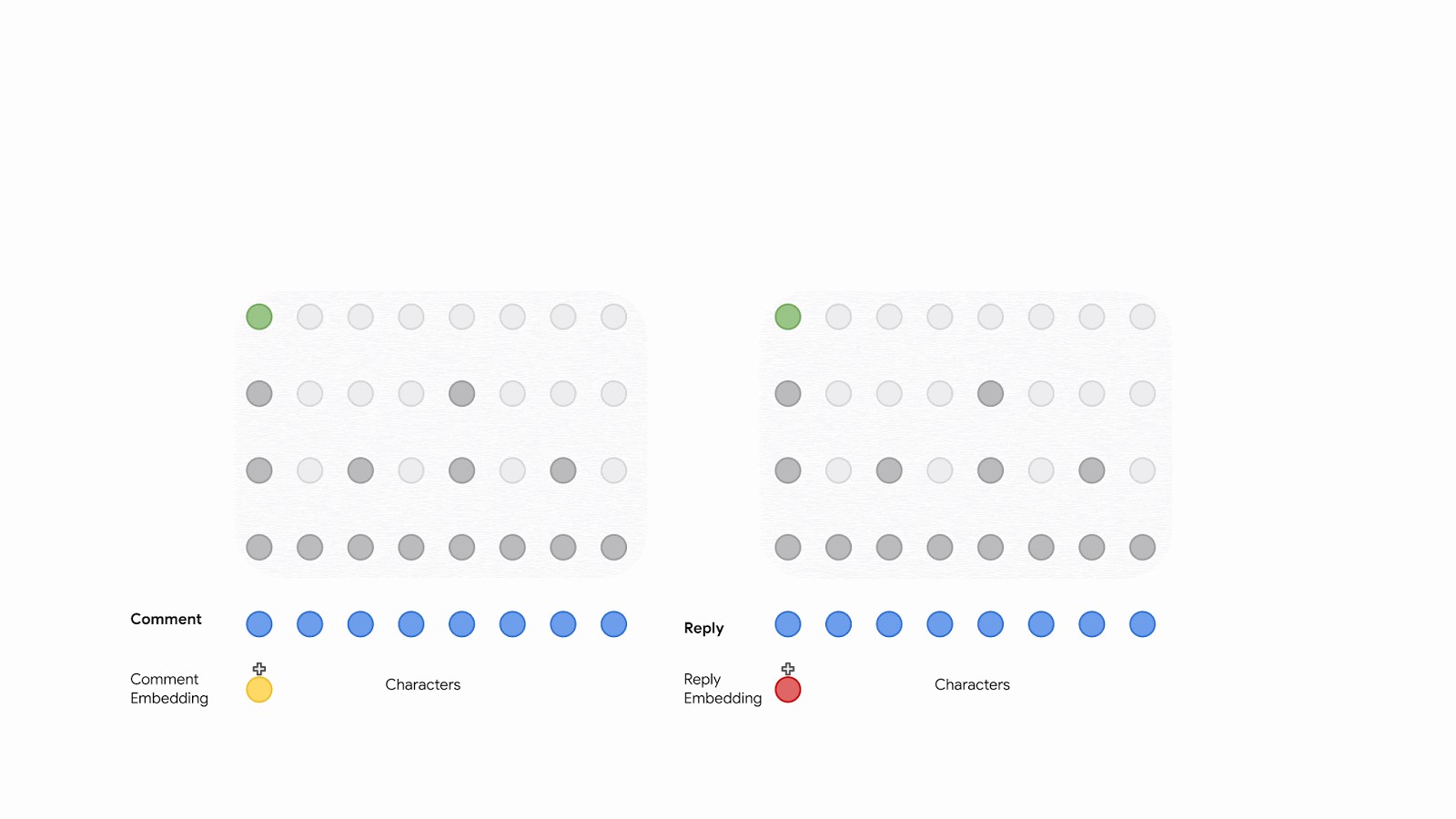
> Contrastive Objective(https://arxiv.org/abs/1705.00652)を通してコメントとその返信の間の相互情報を最大化するデュアルエンコーダーネットワーク。各エンコーダーにはバイトのシーケンスが与えられ、計算効率の高い拡張(dilated)トランスフォーマーネットワークとして実装されています。
すべてを学習するモデル
私たちは、各言語ごとに個別のモデルを学習させるのではなく、サポートされているすべての言語に対して1つのクロスリンガルなモデルを学習させることを選択しました。これにより、コメントで複数の言語が混在してもサポートすることができ、また、たとえば絵文字や数字などの共通言語は、ある言語での学習を他の言語を理解するために活用することができます。さらに、たった1つのモデルにしたことで、メンテナンスやアップデートの計画を簡素化することができました。このモデルは今は英語とスペイン語に展開されていますが、このアプローチには柔軟性があるため、将来的には他の言語への展開も可能になるでしょう。
このモデルによって生成された提案を多言語のエンコーディングで調べてみると、このモデルは適切な回答を、どの言語で書かれているかに関係なくクラスタリングできることが明らかになりました。このようなクロスリンガルな能力は、学習中にモデルがパラレルコーパスに触れることなく現れました。下の図は、3つの言語において、入力されたコメントでモデルが精査されたときに、回答がその意味によってどのようにクラスタリングされるかを示しています。例えば、「This is a great video」という英語のコメントは、「Thanks!」などの適切な返信に囲まれています。さらに、他の言語で最も近い返信を調べると、それらも英語の返信と同じような意味で適切であることがわかります。また、この2D画像では、似たような意味の返信が集まったクロスリンガルのクラスタがいくつか示されています。つまり、このモデルでは、サポートされている複数の言語で豊かなクロスリンガルユーザー体験をサポートできていることが見て取れます。
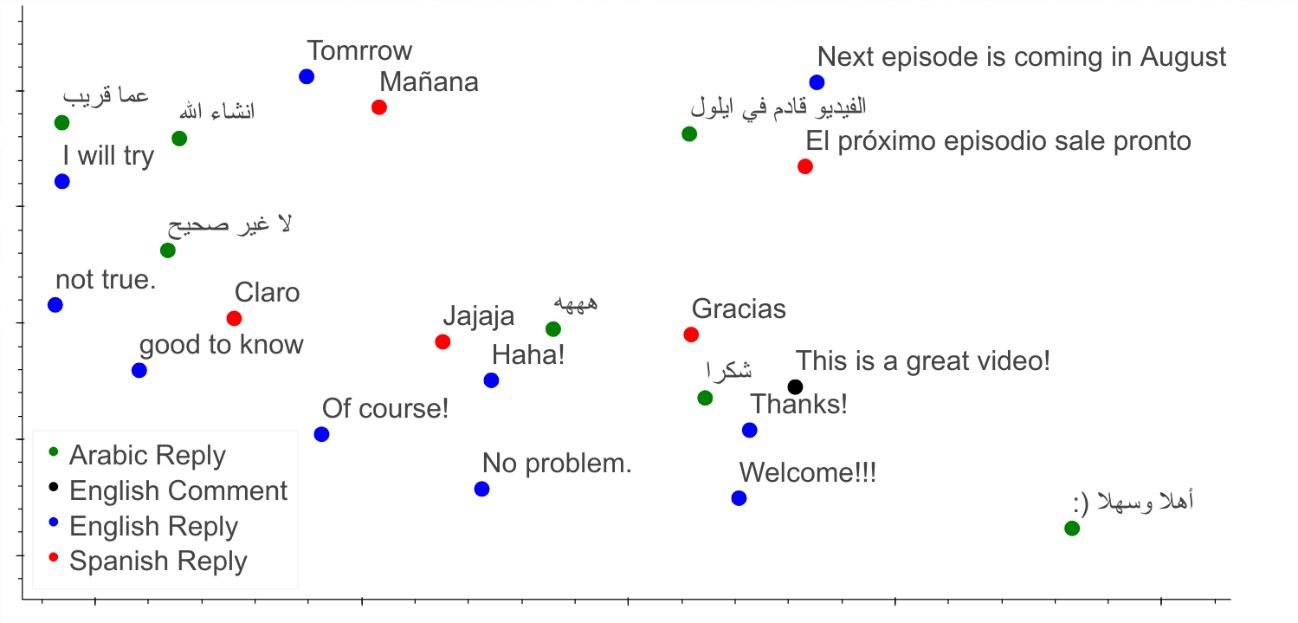
> 仮定コメントと返信候補リストが提供されたときのモデルのエンコーディングの2D画像。英語のコメント(黒色)の周辺には、英語の適切な返信と、スペイン語とアラビア語の対応する返信が置かれています。このネットワークは、パラレルコーパスにアクセスすることなく、英語の返信とその翻訳を整列させるように学習できたことに注目してください。
提案のタイミングは?
私たちの目標はクリエイターを支援することなので、SmartReplyが提案を行うのは有効性が高そうなときに限られるようにしなければなりません。理想的には、作成者がコメントに返信する可能性が高く、モデルが実用的で具体的な回答を提供する可能性が高い場合にのみ、提案を表示するようにしたいです。これを達成するために、どのコメントがSmartReplyを起動すべきかを識別するための補助モデルを訓練しました。
まとめ
英語とスペイン語のコメントからスタートしたYouTube SmartReplyですが、このたびは初のクロスリンガルで、文字バイトベースのSmartReplyをローンチしました。YouTubeは異種様々なコンテンツを生み出す多種多様なユーザーがいるグローバルなプロダクトです。そのため、このグローバルな視聴者のためにコメントを継続的に改善していくことが重要であり、SmartReplyはこの目的への強力な一歩となっています。
※本コラムは以下の文章を意訳したものです。
引用元 http://ai.googleblog.com/2020/07/smartreply-for-youtube-creators.html
※本コラムは原文執筆者が公式に発表しているものでなく、翻訳者が独自に意訳しているものです。

