
オンデバイスのスーパーマーケット商品認識 第05回 20年09月 / 最終更新:2020.09.23
目次
こんにちは。野田貴子です。今回から海外のWeb関連のAIニュースを意訳して紹介していきます。興味がある方はご覧ください。
--
目の見えない人にとって大きな問題の1つは、包装された食品を識別するのが難しいということです。なぜなら、多くの食品は同じような箱や缶や瓶などで包装され、ラベルに印刷された文字や画像を見ないと区別できないためです。しかし、スマートモバイルデバイスのユビキタス化のおかげで、機械学習を活用してこのような課題に対処することができるようになりました。
近年はさまざまな知覚タスクを処理するオンデバイスのニューラルネットワークの精度が大幅に向上し、モバイル端末でも多くの視覚タスクを高いパフォーマンスで実行できるようになりました。MnasNet (https://ai.googleblog.com/2018/08/mnasnet-towards-automating-design-of.html)やMobileNets(https://ai.googleblog.com/2019/11/introducing-next-generation-on-device.html)のようなオンデバイスモデルの開発とオンデバイスインデックスを組み合わせて、食品ラベルの認識のようなコンピュータ視覚システムを端末上でリアルタイムに実行することが可能になりました。
私たちはこのような技術を活用して、視覚障害のあるユーザーが物理的な世界をより楽に過ごすためのAndroidアプリLookoutを最近リリースしました。ユーザーがスマートフォンのカメラを商品に向けるとLookoutが商品を識別し、ブランド名と商品の大きさを音声で伝えます。これを実現するために、LookoutはMediaPipe(https://mediapipe.dev/)のオブジェクトトラッキングとOCRモデルに加えて、オンデバイスの商品インデックスを備えたスーパーマーケット商品検出モデルと認識モデルを搭載しています。これは、オンデバイスでもリアルタイムに動作します。
なぜオンデバイスなのか
オンデバイスのシステムは、インターネット接続に依存しないという利点があります。しかしこの利点を活かすためには、商品を十分にカバーするデータベースを端末内に持たなければなりません。Lookoutが使用するデータセットでは、ユーザーの地理的情報に応じて200万の人気商品が動的に選択されます。
従来のソリューション
コンピュータ視覚を使用した従来の商品認識には、たとえばSIFT(https://en.wikipedia.org/wiki/Scale-invariant_feature_transform)アルゴリズムによって抽出された局所的な画像の特徴が使われてきました。このような、機械学習を使わないアプローチでのマッチングは信頼性がかなり高くなりますが、インデックス画像あたりの保存量が多く、照明不足やピンボケなどの環境の変化に弱いという問題があります。さらに、ほとんどの場合は商品の全体像以上の情報をキャッチできていませんでした。
別のアプローチとしては、機械学習を使用し、商品パッケージのテキストを抽出するために、依頼された画像とデータベースにある画像でOCRシステムを実行することが考えられます。依頼された画像上のテキストはN-Gram(https://en.wikipedia.org/wiki/N-gram)を用いてデータベースと照合し、スペルミス、誤認識、商品パッケージ上の単語の認識ミスなどのOCRエラーをロバストなものにすることができます。また、N-Gramsではテキストの完全一致を要求するのではなく、ジャッカード係数(https://en.wikipedia.org/wiki/Jaccard_index)のような類似度を表す尺度を使用して、要求された文書とインデックス文書が部分的に一致しているとみなすことができます。しかし、OCRでは、TF-IDF(https://en.wikipedia.org/wiki/Tf%E2%80%93idf)のような他の信号と一緒にN-Gramsを格納する必要があるので、インデックスドキュメントのサイズが非常に大きくなる可能性があります。また、OCRとN-Gramの組み合わせでは、2つの異なる商品のパッケージに同じ単語が書かれていると信頼性が下がることが懸念されています。
SIFTやOCR&N-Gramのアプローチとは対照的に、当社のニューラルネットワークベースのアプローチは、各画像に対してグローバル記述子(すなわち埋め込み)を生成し、わずか64バイトしか必要としないため、SIFT機能のインデックス入力で画像1枚あたりに必要な10~40KB、あるいは信頼性の低いOCR&N-Gramのアプローチで画像1枚あたりに必要な数KBのストレージ要件を大幅に削減します。各インデックス画像で消費されるバイト数が少ないため、より多くの商品をインデックスの一部として含めることができ、ユーザー体験をより向上させることができます。
設計
Lookoutシステムは、フレームキャッシュ、フレーム選択、検出、物体追跡、埋め込み、インデックス検索、OCR、スコア付け、結果発表で構成されています。
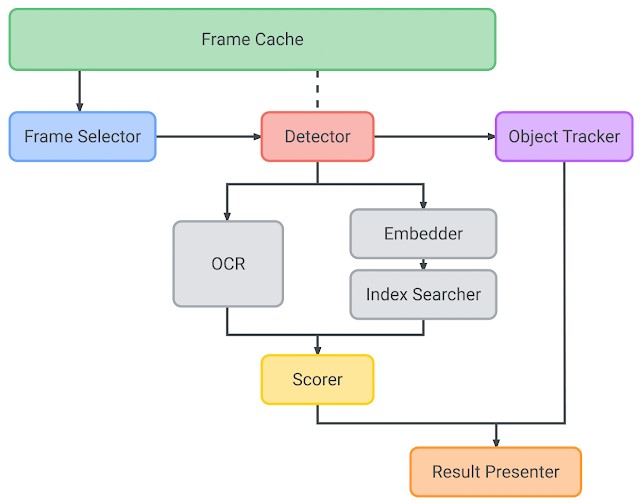
商品認識パイプラインの内部アーキテクチャ
フレームキャッシュ(Frame cache)
フレームキャッシュは、パイプライン内の入力カメラフレームのライフサイクルを管理します。他のモデルコンポーネントから要求された画像などのデータを効率的に配信し、同じカメラフレームの変換が重複しないようにデータのライフサイクルを管理します。
フレーム選択(Frame selector)
ユーザーがカメラのファインダーを商品に向けると、軽量なIMUベースのフレーム選択が実行されます。これは、角度回転率(度÷秒)で測定されるジッタに基づいて、連続的に入力される画像ストリームから、特定の品質基準(たとえば、画質とレイテンシのバランス)に最も適合するフレームを選択します。このアプローチは、高品質な画像フレームのみを選択的に処理し、ぼやけたフレームをスキップすることで、電力消費を最小限に抑えることができます。
検出(Detector)
選択された各フレームは商品検出モデルに渡され、フレーム内の関心領域(検出境界エリア)を提案します。検出モデルのアーキテクチャは、高品質と低レイテンシーのバランスをとるために、MnasNet(https://arxiv.org/abs/1807.11626)バックボーンを使用したシングルショットの検出器になっています。
物体追跡(Object tracker)
MediaPipe Boxの追跡(https://ai.googleblog.com/2018/02/the-instant-motion-tracking-behind.html)は、検出されたエリアをリアルタイムで追跡するために使用され、ある物体の検出から別の物体の検出の間のギャップを埋め、検出頻度を減らし、電力消費量を抑えるために重要な役割を果たします。また、物体追跡は実行時にそれぞれの物体にIDを割り当てており、後の結果発表の際に同じ物体の発表を繰り返さないようになっています。それぞれの検出結果について、物体追跡では検出結果と既存の物体境界エリアとの間の Intersection over Union(https://en.wikipedia.org/wiki/Jaccard_index)(IoU)を使用して、物体を新規登録するか、既存の物体を更新するかを決めます。
埋め込み(Embedder)
検出器からの関心領域(ROI)を受け取った埋め込みモデルは、64次元の埋め込み値を計算します。埋め込みモデルは最初に大規模な分類モデル(つまりNASNet(https://ai.googleblog.com/2017/11/automl-for-large-scale-image.html)に基づく教師モデル)から学習されます。埋め込み層は入力画像を「埋め込み空間」(2つの点が近いと画像が視覚的に似ているということを表すベクトル空間のこと)に投影します。埋め込みのみを分析するため、モデルが柔軟であり、新しい商品に拡張するたびに再学習する必要がないことが保証されます.しかし、教師モデルは端末上で直接使用するには大きすぎるため、これを使ってより小さく省エネな学生モデルを訓練します。最後に、主成分分析(PCA)を適用して埋め込みベクトルの次元数を256から64に減らし、オンデバイスで保存するための埋め込みを合理化しています。
インデックス検索(Index searcher)
インデックス検索は、要求された埋め込みを用いて、あらかじめ構築された互換性のあるScaNN(https://ai.googleblog.com/2020/07/announcing-scann-efficient-vector.html)インデックスに対してKNN検索(https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm)を行います。その結果、商品名や包装サイズなどのメタデータを含む最上位のインデックス文書が返されます。インデックス検索の待ち時間を短縮するために、すべての埋め込みはk-means(https://en.wikipedia.org/wiki/K-means_clustering)でクラスタ化されています。要求時には、実際の距離を計算するために、関連するデータのクラスタがメモリに読み込まれます。品質を犠牲にすることなくインデックスサイズを小さくできるため、インデックス作成には直積量子化(https://lear.inrialpes.fr/pubs/2011/JDS11/jegou_searching_with_quantization.pdf)を利用しています。
OCR
OCRは、商品サイズや味の種類などの追加情報を抽出するために、各カメラフレームのROI上で実行されます。従来のソリューションではインデックス検索にOCR結果を使用していましたが、ここではスコア付けのみに使用しています。OCRテキストに基づいた適切なスコア付けアルゴリズムによって、スコア付け機能(下記参照)は正しい結果を決定し、特に類似商品がある場合に精度を向上させます。
スコア付け(Scorer)
スコア付けは、埋め込み(インデックス結果を含む)とOCRモジュールからの入力を受けて、以前に検索されたインデックス文書(インデックス検索を介して検索された埋め込みデータとメタデータ)のそれぞれにスコア付けを行います。スコア付け後の上位の結果が、システムからの最終結果となります。
結果発表(Result presenter)
結果発表では、上記の結果をすべて取り込み、音声合成サービスを利用して商品名をユーザーに伝えます。

スイスのスーパーマーケットにおけるオンデバイス商品認識の初期実験
結論と今後の課題
ここで解説したオンデバイスシステムは、商品の詳細情報(栄養情報、アレルゲンなど)の表示、顧客評価、商品比較、スマートショッピングリスト、価格追跡など、さまざまな新しいインストア体験を可能にするために使用することができます。私たちは、これらの将来的なアプリケーションを探求するとともに、基礎となるオンデバイスモデルの品質とロバスト性を向上させるための研究を続けています。
※本コラムは以下の文章を意訳したものです。
引用元 http://ai.googleblog.com/2020/07/on-device-supermarket-product.html
※本コラムは原文執筆者が公式に発表しているものでなく、翻訳者が独自に意訳しているものです。

